everything i kown about PID
PID算法原理
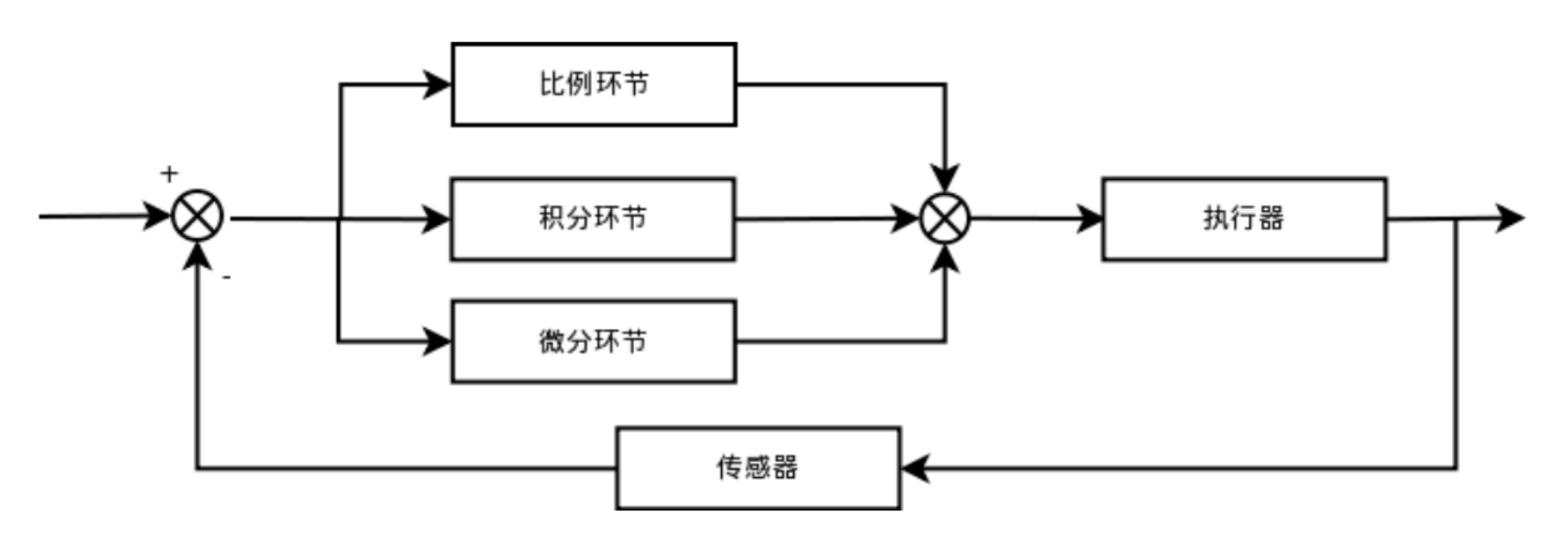
算法简易原理图
PID 本质上是一个基于误差的反馈控制器.
核心公式
先定义几个量:
- 设定值:
rin(t) - 实际输出:
rout(t) - 误差:
err(t) = rin(t) - rout(t)
控制器输出:
这里的 u(t) 就是控制量。
u(t)在工程里实际是:
PWM 占空比
电压参考值
电流参考值
力矩参考值
所以 PID 的输出必须和执行器建立映射关系。
三个环节
比例P
看当前误差有多大,误差大就给大一点的控制,误差小就给小一点的控制。
作用:
- 提高响应速度
- 快速把系统往目标拉过去
问题:
Kp太大会超调、震荡Kp太小会反应迟钝
积分I
积分看的是误差的累积。
哪怕误差一直很小,只要长期存在,积分项就会慢慢变大,把系统继续往目标推。
作用:
- 消除稳态误差(静差)
问题:
- 容易积分累积过多,造成积分饱和
- 会带来超调
微分D
微分看的是误差变化趋势。
如果误差正在快速变小或变大,微分项就提前做出反应。
作用:
- 抑制超调
- 改善动态性能
- 提前“刹车”
问题:
- 对噪声敏感
Kd太大可能让系统抖动,或者响应变慢
PID算法的离散化
单片机不可能真正连续计算,它是每隔一个采样周期 T 算一次,所以必须把连续 PID 变成离散 PID
离散后的三个环节
设采样周期为 T,第 k 次采样时:
比例P
积分I
积分用累加代替:
微分D
微分用差分代替:
离散PID公式
两种离散形式
位置型PID
直接算当前位置的控制输出 u(k)。
特点:
- 输出是“完整控制量”
- 积分项容易越积越大
增量型PID
不直接算 u(k),而是算:
最后:
增量型离散式和最近三次误差有关:
特点:
- 只和最近几次误差有关
- 不容易因为积分累计导致数值过大
位置型 PID 的 C 语言实现
前置工作
为了方便举例,定义一个结构体并初始化:
1 |
|
实际调参时主要调Kp,Ki,Kd这三个值。
核心控制算法
位置型 PID 的核心代码思想是(伪代码):
1 | err = SetSpeed - ActualSpeed; |
- 先算当前误差
- 再把误差累加进积分项
- 然后按 PID 公式求控制量
- 保存本次误差供下一次微分用
搭配前面结构体的实际代码:
1 | /* 位置型 PID 计算函数 */ |
main函数
1 | int main(void) |
增量型 PID 的 C 语言实现
增量型不是直接求控制输出,而是求:
代码本质类似:
1 | increment = Kp*(err - err_next) |
具体代码结构跟位置型相似,参考上一节即可。
积分分离PID
背景
这个改进是为了解决一个很经典的问题: 误差特别大时,积分项不应该参与太多。
在启动阶段、目标突变阶段,误差往往很大。
如果这时还疯狂积分,就会导致:
- 积分项积得很大
- 控制器输出过大
- 超调严重
- 甚至震荡
所以思路是:
- 误差大:关闭积分
- 误差小:开启积分
代码实现逻辑
相当于在积分项前面加一个开关
1 | if(abs(err) > 200) |
然后:
1 | voltage = Kp*err + index*Ki*integral + Kd*(err-err_last); |
抗积分饱和 PID
背景
当执行器有物理极限时,比如:
- PWM 占空比最多 100%
- 电压最多 24V
- 电流最多 10A
如果 PID 还在不断因为误差大而累加积分,控制器内部 u(k) 会越来越大,但执行器根本做不到,这就叫积分饱和。
核心思想
先判断控制输出是否已经超限:
- 如果已经大于上限,只允许累加负误差
- 如果已经小于下限,只允许累加正误差
- 如果在正常范围,正常积分
伪代码:
1 | if (输出 > 上限) |
梯形积分PID
背景和定义
最简单积分是矩形积分:
它的积分精度有限。 如果想积分更精确,可以用数值分析里的梯形积分。
矩形积分只看当前误差。
梯形积分看的是当前误差和上一次误差的平均值。
更像是:
这样能让数值积分更准确。
核心代码修改
只需要把原来的积分项改成:
1 | pid.Ki * pid.integral / 2 |
变积分PID
这是比积分分离更一般化的一种方法
核心思想
普通 PID 里 Ki 是常数。
但实际中应该是:
- 误差大时,积分慢一点甚至没有
- 误差小时,积分快一点
所以变积分就是:
其中 index 随误差变化。
例子:
|err| < 180:index = 1180 < |err| < 200:index = (200 - |err|)/20|err| > 200:index = 0
所以:
- 误差很大:完全不积分
- 误差中等:积分逐渐变弱
- 误差很小:全积分
测试结果显示,变积分 PID 稳定很快。
专家 PID 与模糊 PID
这一节开始进入“智能调参”思想。
背景
普通 PID 的难点不是公式,而是:
Kp怎么调Ki怎么调Kd怎么调
如果系统是:
- 非线性的
- 模型不明确的
固定参数 PID 可能不够好。
于是就引入:
- 专家 PID
- 模糊 PID
专家PID
本质
利用经验规则去动态调整 PID 参数或控制策略
比如:
- 误差特别大 → 先别积分
- 误差在变大 → 增大比例
- 误差很小 → 加强积分
- 接近稳定 → 保持输出
前面看到的:
- 积分分离
- 变积分
- 抗积分饱和
都可以看成专家规则的特例。
主要判断依据
e:误差大小(反映偏得多远ec:误差变化率(反映偏差变化趋势
核心控制算法
1 | float ExpertPID_Realize(ExpertPID *pid, float target, float actual) |
模糊算法
模糊算法不是真的“模糊”
它不是乱调,而是把人类经验语言数学化。
比如你平时会说:
- 误差很大
- 误差有点大
- 误差中等
- 误差很小
这些词虽然不是精确数值,但人能理解。
模糊控制就是让程序也能理解这种“语言规则”。
隶属度
隶属度是一个 0~1 之间的数,用来表示:
某个输入值,对某个模糊概念的“符合程度”有多大。
比如对 6° 来说,可以设定:
- 属于“小”的隶属度 =
0.3 - 属于“中”的隶属度 =
0.7 - 属于“大”的隶属度 =
0
意思就是:
- 它有一点像“小”
- 更像“中”
- 完全不像“大”
隶属函数
隶属函数就是把一个精确输入映射成“属于某个模糊集合的程度”的函数。
隶属度范围通常在 [0,1]。
本质
模糊 PID 不是直接替代 PID,
而是根据误差 e 和误差变化率 ec 去在线调整Kp,Ki,Kd。
所以本质是:
模糊控制负责调参数,PID 负责执行控制。
调参规则
到底应该怎样根据系统状态调整 Kp, Ki, Kd?
- 当前误差
e - 误差变化率
ec
我们制定规则:
- 如果
e很大,ec也在变大
→ 增大Kp,减小Ki,适当给Kd - 如果
e很小,但还有静差
→ 增大Ki - 如果系统正在快速逼近目标,可能超调
→ 增大Kd,适当减小Kp
核心控制算法
1 | float FuzzyPID_Realize(FuzzyPID *pid, float target, float actual) |