everything i should kown before learning control
C语言从源代码到.bin和.hex等机器代码的编译和链接过程
目标
把你写的“人能看懂的 C 代码”,一步步变成“CPU 能按地址执行的机器码”,再打包成适合烧录的文件。
链路
.c/.h 源码 → 预处理后 .i → 编译后.s → 汇编 → 目标文件 .o → 链接 → 可执行映像 .elf → 转换成 .bin/.hex
预处理:处理 #include、#define、条件编译
这一步由预处理器完成。
它主要做三件事:
- 把
#include的头文件内容展开 - 把
#define宏替换掉 - 处理
#ifdef/#ifndef/#if这些条件编译
比如:
1 |
|
预处理后会变成:
1 | int a = 5; |
再比如:
1 |
会把 my.h 里的内容直接展开到当前位置。
这一步后的结果常见可看成 .i 文件。
这一步还没有生成机器码,只是把源码“整理展开”。
编译:把 C 代码变成汇编代码
这一步由编译器完成.
它会做:
- 词法分析
- 语法分析
- 语义分析
- 优化
- 把 C 语言翻译成汇编语言
例如这段 C:
1 | int add(int a, int b) |
可能会被编译成类似这样的汇编:
1 | add: |
这一步后的结果常见是 .s 文件。
这里要注意:
- 编译器还不负责决定最终放到 Flash 哪个地址
- 它只是先把每个源文件各自翻译成汇编
汇编:把汇编代码变成机器指令
这一步由汇编器完成。
它把:
1 | ADD r0, r0, r1 |
变成 CPU 真正认识的二进制机器码。
生成的文件通常是:
.o:目标文件 object file
这时的 .o 文件里已经有机器码了,但还不是最终可烧录程序,因为它通常还存在几个问题:
- 各个函数和变量地址还没完全定死
- 不同源文件之间的调用关系还没完全接好
- 没决定哪段代码放 Flash、哪段数据放 RAM
目标文件 .o 里到底有什么
常见段有:
.text:代码段,放机器指令,一般进 Flash.rodata:只读常量,比如字符串常量,一般进 Flash.data:已初始化的全局/静态变量,运行时在 RAM,但其初值通常存放在 Flash.bss:未初始化的全局/静态变量,运行时在 RAM,不占初始镜像空间- 符号表:函数名、变量名等
- 重定位信息:告诉链接器哪些地方后面还要修正地址
比如你写:
1 | int g1 = 10; // .data |
链接:把一堆 .o 拼成一个完整程序
这一步由链接器 linker完成
它主要做四件大事:
合并各个目标文件
比如:
main.ogpio.odelay.ostartup_stm32.o
这些都要合并成一个完整程序。
解析符号引用
例如:
main.c 里调用了:
1 | HAL_Init(); |
但 HAL_Init 的实现不在 main.c,而在别的 .o 或库文件里。
链接器会找到它的真正定义,把调用接上。
如果找不到,就会报:
1 | undefined reference to `HAL_Init` |
这就是符号未定义错误。
分配最终地址
链接器要决定:
main()放在 Flash 哪个地址- 中断向量表放在哪里
.data放 RAM 哪个地址.bss放 RAM 哪个地址- 堆栈从哪里开始
这些规则通常写在链接脚本里,比如 .ld 文件。
举个 STM32 常见思路:
- Flash 起始:
0x08000000 - RAM 起始:
0x20000000
那么链接器可能安排:
.isr_vector放0x08000000.text紧跟其后放 Flash.data、.bss放 RAM
重定位
前面 .o 文件里有些地址还不确定。
例如某条指令要跳转到 func(),在单独编译某个源文件时,还不知道 func() 最终地址。
链接器在知道全局布局后,会把这些地址全部修正好。
这一步叫重定位 relocation。
为什么嵌入式必须要有启动文件和链接脚本
因为单片机不是操作系统帮你“加载程序”,而是上电后直接从固定地址开始执行。
所以程序必须提前安排好:
- 第一条指令在哪里
- 初始栈顶在哪里
- 中断向量表在哪里
main()怎么被调用.data怎么从 Flash 拷到 RAM.bss怎么清零
这通常靠两样东西完成:
启动文件 startup
一般是汇编文件,比如:
1 | startup_stm32f407xx.s |
它负责:
- 定义中断向量表
- 设置初始栈指针 MSP
- 进入
Reset_Handler - 在
Reset_Handler中初始化运行环境 - 最后调用
main()
上电后,CPU不是直接进 main(),而是先走启动文件。
链接脚本 linker script
比如:
1 | STM32F407VGTx_FLASH.ld |
它负责告诉链接器:
- Flash 多大
- RAM 多大
- 各段放哪
- 栈和堆怎么留空间
没有它,链接器不知道怎么给嵌入式程序排地址。
链接后的产物:.elf
.elf 文件可以理解成:“完整的、可调试的程序文件”
里面通常有:
- 完整机器码
- 各段地址信息
- 符号表
- 调试信息(如果没去掉)
- 重定位后的结果
所以开发时最核心的产物其实往往是 .elf,不是 .bin。
链接时还经常生成:
.map文件你能在里面看到:
- 哪个函数占了多少 Flash
- 哪个全局变量占了多少 RAM
- 各段的地址分布
- 最终程序大小
嵌入式里排查“Flash 爆了”“RAM 爆了”时,
.map很有用。
.elf 到 .bin、.hex
.elf 虽然完整,但它比较复杂,不适合直接拿来给某些烧录器裸写。
所以会再做一步格式转换。
.bin
.bin 是最简单的格式:
- 纯二进制
- 没有太多附加信息
- 基本就是“按顺序排好的原始字节流”
特点:
- 体积小
- 简单
- 但不自带地址信息
所以烧录 .bin 时,通常你要告诉烧录工具:
把这个 bin 从
0x08000000开始写进去
也就是说:.bin = 纯数据本体
.hex
.hex 常指 Intel HEX 格式
它本质上是:
- 用 ASCII 文本表示二进制数据
- 每一行都带地址、数据长度、校验和
特点:
- 是文本文件,可读性比
.bin强一点 - 自带地址信息
- 适合传输和烧录
so:
.hex = 带地址信息的文本化机器码
.bin 和 .hex 的区别
.bin不带地址.hex带地址
所以:
- 烧
.bin时,经常要额外指定起始地址 - 烧
.hex时,工具一般能根据文件里的地址直接烧
STM32 上电后程序是怎么跑起来的
烧录
把 .bin 或 .hex 的内容写进 Flash。
上电复位
CPU 从固定启动地址取数据。对 Cortex-M 来说,通常从中断向量表开始。
向量表最前面一般是:
- 初始栈顶地址
Reset_Handler地址
执行 Reset_Handler
启动代码开始跑,做这些初始化:
- 设置栈
- 拷贝
.data初值到 RAM - 清零
.bss - 可能初始化时钟库环境
- 调用
SystemInit() - 调用
main()
进入 main()
CPU 上电后不是直接执行 main,而是先执行启动代码。
完整实例
假设你有:
main.cled.cdelay.cstartup_stm32f4xx.sstm32_flash.ld
那么构建过程就是:
分别编译
main.c → main.oled.c → led.odelay.c → delay.ostartup_stm32f4xx.s → startup_stm32f4xx.o
链接
- 把这些
.o按stm32_flash.ld的规则排布 - 得到
project.elf
格式转换
project.elf → project.binproject.elf → project.hex
烧录
- 把
.bin或.hex烧进 MCU Flash
运行
- 上电
- 执行启动文件
- 进入
main()
C语言的内存模型
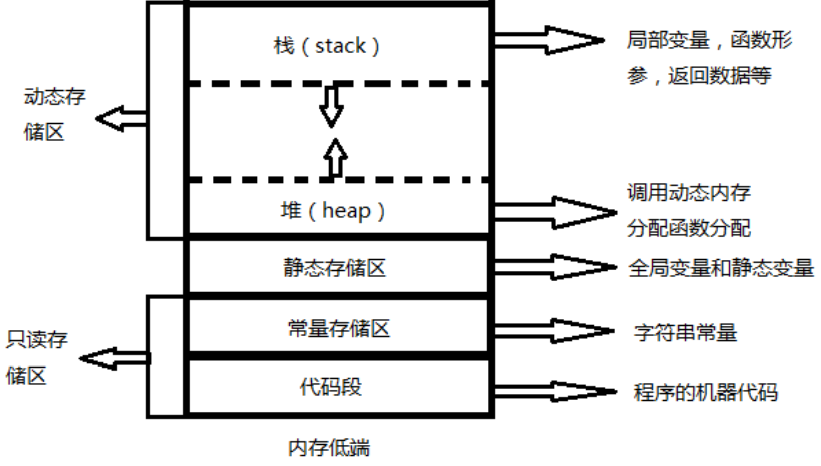
可以把 C 语言的内存模型 理解成:
程序运行时,数据会被放在不同“区域”里,每个区域用途不同、生命周期不同。
代码区
放的是程序的机器指令,也就是编译后的函数代码
1 | int add(int a, int b) { |
add 这个函数对应的指令,一般就在代码区。
特点:
- 通常是只读
- 程序运行期间一直存在
- 多个函数的代码都在这里
全局/静态存储区
1 | int g1 = 10; // 已初始化全局变量 |
特点:
- 生命周期是整个程序运行期间
- 不会因为函数结束而消失
它又常分成两部分:
已初始化数据区 .data
放已经明确赋初值的全局/静态变量:
1 | int g1 = 10; |
未初始化数据区 .bss
放未初始化的全局/静态变量:
1 | int g2; |
栈区
栈里主要放:
- 局部变量
- 函数参数
- 返回地址
- 一些临时数据
1 | void func(void) { |
这里的 a、b 一般就在栈上。
特点:
- 进入函数时分配
- 函数结束时自动释放
- 由编译器自动管理
- 空间通常较小
一般来说,直接通过变量访问栈内存,速度最快(对于单片机)
RTOS创建任务的时候也会为每个任务分配一定的栈空间,它会替代MCU的硬件裸机进行内存的分配。可以在CubeMX中设置。如果一个任务里定义了大量的变量,可能导致实时系统运行异常,请增大栈空间。
开发板C型使用F407IG芯片,片上RAM的大小为1MB。
堆区
堆是程序员手动申请、手动释放的内存区域。
1 | int *p = (int *)malloc(sizeof(int)); |
这里 malloc 申请的内存就在堆上。
特点:
- 生命周期由你控制
- 不会因为函数结束自动释放
- 适合动态大小的数据
- 如果忘记
free,会造成内存泄漏
在CubeMX初始化的时候,Project mananger标签页下有一个Linker Setting的选项,这里是设置最小堆内存和栈内存的地方。如果你的程序里写了大规模的数组,或使用
malloc()等分配了大量的空间,可能出现栈溢出或堆挤占栈空间的情况。需要根据MCU的资源大小,设置合适的stack size和heap size。
常量区
字符串常量、只读常量通常放这里。
1 | char *p = "hello"; |
"hello" 这个字符串常量一般放在常量区,而 p 这个指针变量本身如果是局部变量,通常在栈上。
对比:
1 | char *p = "hello"; |
如果要改,应该写
1 | char p[] = "hello"; |
这时数组 p 是可修改的,通常在栈上(如果是局部数组)
完整实例
1 |
|
Debug外设工作原理
Debug外设是 MCU 里专门给“调试”准备的一组硬件模块(不是你写的软件库)
可以理解为:
- 通过 SWD/JTAG 和外部调试器(J-Link/ST-Link)连接
- 在不改你业务代码的情况下,做断点、单步、读写内存、观察变量、跟踪执行
- 常见模块:FPB(硬件断点)、DWT(数据监视/计数器)、ITM/TPIU(调试信息输出通道)
和普通外设(USART、SPI、TIM)区别是:
普通外设服务业务功能;Debug外设服务开发调试流程。
原理图
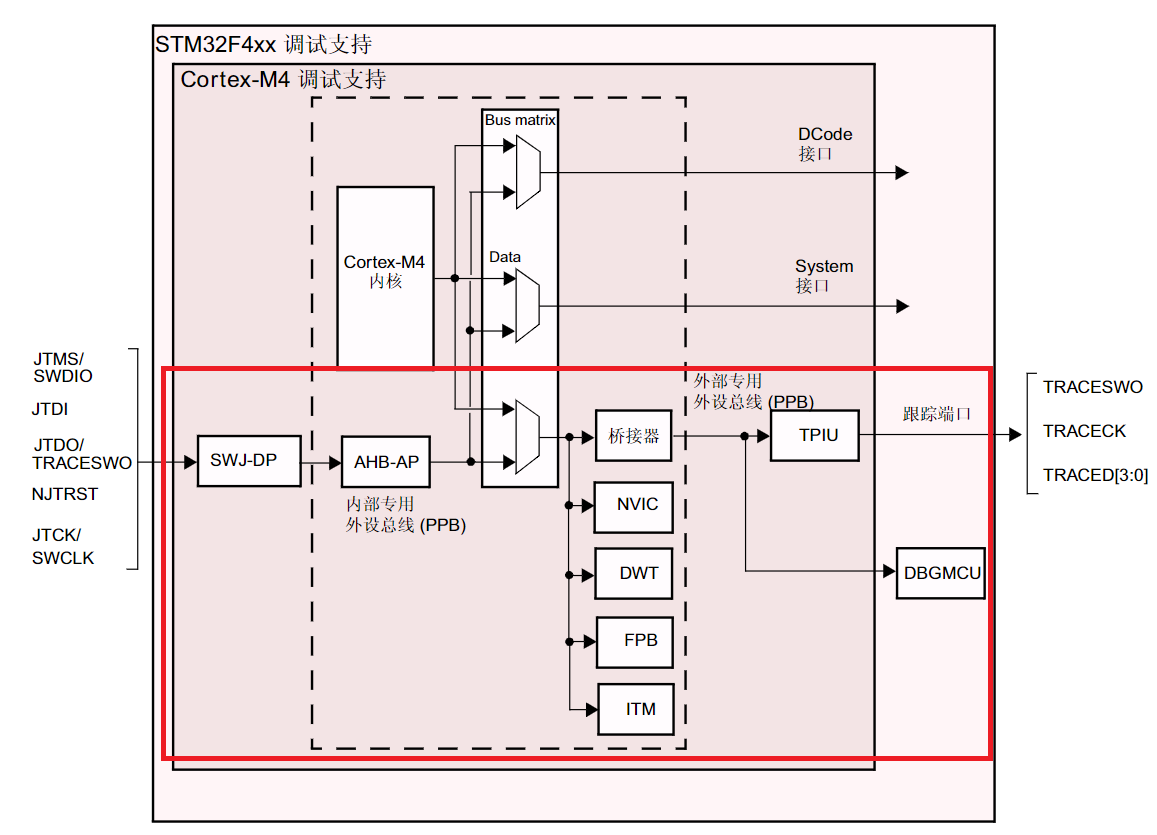
DBG支持模块(红框标注部分,也可以看作一个外设)通过一条专用的AHB-AP总线和调试接口相连(Jtag或swd)
桥接器与数据和外设总线直接相连,还同时连接了中断嵌套管理器(因此同样可以捕获中断并进行debug)和ITM、DWT、FPB这些调试支持模块。
DBG可以直接获取内存或片上外设内的数据而不需要占用CPU的资源(调试器可通过调试访问端口直接读写内存/寄存器,不需要你写额外业务代码去搬运数据)
数据通过专用外设总线(PPB)发送给调试器,进而在上位机中读取。
FPB(Flash Patch and Breakpoint)
闪存指令断点
- 负责硬件断点,尤其是 Flash 代码断点。
- 命中后触发 debug 事件让内核停下。
- 断点数量有限(M4 常见硬断点数量不多,通常几个)。
当CPU的指令寄存器读取到某一条指令时,FPB会监测到它的动作,并通知TPIU暂停CPU进行现场保护
DWT(Data Watchpoint and Trace)
数据观察与追踪单元:用于比较debug变量的大小,并追踪变量值的变化。
当你设定了比较断点规则(当某个数据大于/小于某个值时暂停程序)或将变量加入watch进行查看,DWT就会开始工作
DWT还提供了一个额外的计时器,即所有可见的TIM资源之外的另一个硬件计时器(因为调试其他硬件定时器的计时由于时钟变化可能定时不准,而DWT定时器是始终正常运行的),用于给自身和其他调试器模块产生的信息打上时间戳。
BSP中也封装了DWT计时器,你可以使用它来计时。
BSP 是 Board Support Package,中文常叫“板级支持包”。
意思是:一套针对你这块开发板的底层适配代码,通常包含:
- 时钟/引脚/启动配置
- 外设驱动封装(GPIO/UART/SPI/CAN等)
- 常用工具(比如你文里说的 DWT 计时器封装)
作用是把“芯片和板子差异”封起来,让上层应用代码更通用。
ITM(instrument trace macrocell)
指令追踪宏单元
- 提供非阻塞式的日志发送支持(相当于大家常用的串口调试),SEGGER RTT就可以利用这个模块,向上位机发送日志和信息。
SEGGER RTT是 Real-Time Transfer,即 SEGGER 提供的一种“调试口实时通信机制”可理解成:
- 用 J-Link 调试链路在 PC 和 MCU RAM 间传输数据
- 常用于实时日志打印、命令交互
- 比串口 printf 更快、对实时性影响更小(通常无需占用 UART 外设)
- 追踪CPU执行的所有指令,这也被称作trace(跟踪),并将执行过的指令全部通过调试器发送给上位机。
当debug无法定位bug所在的时候,逐条查看cpu执行的指令是一个绝佳的办法,特别是你有大量的中断或开启了实时系统时。
以上三个模块都需要通过TPIU(trace port interface unit)和外部调试器(j-link等)进行连接,TPIU会将三个模块发来的数据进行封装并通过DWT记录时间,发送给上位机。
GDB调试MCU原理
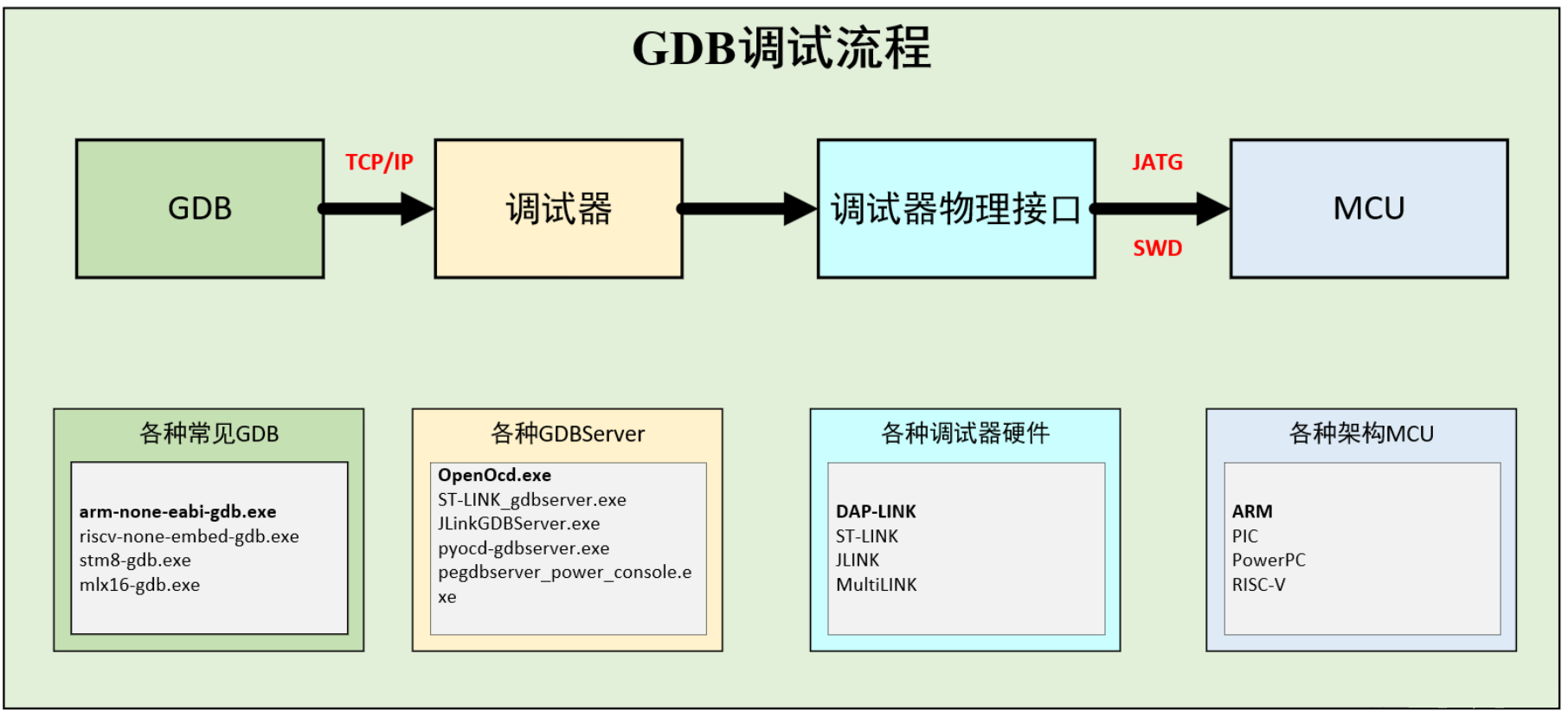
主旨:不同IDE前端不重要,底层都是“调试器 + 调试协议 + 目标芯片”在协作。
工具分工
GDB:调试客户端(下断点、读变量、单步)。GDB Server:桥接层(把GDB命令翻译成J-Link/ST-Link对芯片的操作)。硬件调试器:物理链路(SWD/JTAG)。MCU:被调试目标。
流程本质
- 启动 GDB Server(通常监听一个本地 TCP 端口)。
- GDB 连接这个端口。
- 下发 load/reset/break/continue 等命令。
- Server 驱动探针操作 MCU 的 DBG 能力。
调试时通常由调试服务器(如 J-Link GDB Server)开放 TCP 端口,GDB/IDE 连接后把断点、单步、读写内存等请求经探针转发到 MCU 的 SWD/JTAG 调试硬件上,程序一般从复位入口启动并最终进入 main(attach 场景除外)
当然你也可以选择从其他启动点开始执行,调试器开始执行的位置叫做entry point。同样,在MCU已经正在运行程序的时候,可以attach到程序上开始监控。
而对于直接运行在电脑上的程序(.exe),就不需要GDBserver和物理调试器,GDB程序可以直接访问电脑上运行的程序和CPU的寄存器等。
字节对齐
意义
性能
- 对齐访问通常更快;未对齐可能需要多次总线访问。
正确性/稳定性
- 某些 MCU 或指令对未对齐访问会触发异常(HardFault)或行为受限。
协议与寄存器映射
通信帧、Flash存储格式、寄存器镜像常要求“字节级精确布局”。
结构体默认会填充字节,不讲对齐就会“发出去的数据和预期不一致”。
跨编译器一致性
- 不同编译器/选项对结构体填充可能不同。
例如:
- STM32(32位内核)对“按4字节边界对齐”的32位数据访问最快。
- 内存是按字节编址的,所以一个 float(4字节)可能落在“非4字节对齐地址”。
- 一旦不对齐(比如跨了边界),CPU往往要分两次读再拼起来,访问更慢,某些场景还可能有异常风险。
- 所以编译器会默认给结构体加填充,尽量让成员对齐,提高效率和稳定性。
#pragma pack()设置字节对齐
arm gnu gcc编译器支持通过#pragma pack()来设置字节对齐,支持的对齐参数包括空/1/2/4/8,会启动对应长度的对齐方式。用于通信的结构体(串口/CAN/spi等外设接收数据的时候都是连续的,不会像结构体一样被编译器对齐)在声明时,采用如下的方式:
1 |
|